

I saw a nifty link that Antonio Romero, one of Oracle's OWB product managers, gave out. When I sat in the Publisher's and Author's round table event at the last Open World, I was lucky to sit with the head of Oracle's documentation and discuss a bit on the online documentation structure, and changes coming. As well, I heard from OWB PMs that the OWB docs would be filled out more. Here is the start of that effort, in chapter 7 - Retrieving Data From SAP Sources.
Antonio kindly brought this to attention recently.
Subscribe To This
Monday, December 8, 2008
Oracle Warehouse Builder and SAP Sources
Wednesday, November 19, 2008
Paper accepted for ODTUG Kaleidoscope 2009
Someone out there likes me, and I'll need to find out who. But the good news is that I get to share with the community some 'lessons learned' and case studies related to OWB. My paper was an early accptance to the ODTUG 2009 Kaleidoscope conference, and I am grateful for that. The list of people already accepted is quite an accomplished group. I sincerely hope that OWB 11gR2 is released and available by that point in time, as I will then get to discuss those new features along with 11gR1/1ogR2. Although the case study aspect will not be possible for 11gR2 since it is only in beta.
So come on out to ODTUG's 2009 confernece and find out how OWB can be put to some serious use...after all, we won the 2008 Oracle Partner of the Year Titan Award in Business Intelligence and OWB was a HUGE part of that.
Wednesday, October 29, 2008
Grants, Grants, and More Grants - WITH GRANT OPTION
ORA 01720 grant option does not exist for....
Simple mistake, but easy to fall into.User_A creates a view called AV. This view accesses some of User_A's objects but also accesses one of User_B's tables too (table name is BT). No problem, User_A had been granted select on that table (BT) from User_B:
(as User_B) GRANT SELECT ON USER_B.BT TO USER_A
Now, however, User_A wants to grant select on that view, AV to a third user...User_C.
Even if User_C had also been granted select on User_B.BT table, USER_A would not be able to simply say:
(as User_A) GRANT SELECT ON USER_A.AV TO USER_C
instead you'll see:
ORA 01720 grant option does not exist
What this means is that USER_A tried to grant access to one of USER_B's tables to USER_C through the view AV. Even though USER_C had been directly granted select on USER_B.BT from USER_B itself, you'll still see the above error message.Only the schema that owns the object can grant privileges to that object unless the 'with grant option' is included in the command. The 'with grant option' allows you to give the user that receives the grant (with the grant option) the ability to grant that same privilege to other users too. In a way, it is like giving a bit of your authority on one of your own objects to another trusted schema. Here is an example of the use of the with grant option:
(As USER_B) GRANT SELECT ON USER_B.BT TO USER_A WITH GRANT OPTION
What this did was it allowed USER_A to then grant USER_C select access to USER_B.BT table. It ALSO indirectly allows USER_A to grant select on USER_B.BT table through the view, USER_A.AV.
You can now perform the following with no problems:
(as User_A) GRANT SELECT ON USER_A.AV TO USER_C
Wednesday, October 1, 2008
Oracle Enterprise Linux, Ubuntu Linux, and more Linux

So I've been building a few Virtual Machines using Oracle VM as well as VMWare using different distros of Linux to see the major fuss between them all. Seems everyone has a favorite.
At least from an Install point of view, Ubuntu was easily smoother, however OEL offered many more installation and configuring options to start right away. This I liked. I have to be honest, I could care less how pretty and customizable Ubntu seems to be if OEL can run Oracle software better in any way. I'll keep posting anything that I find to be a deal breaker for me. I am just looking for the best of breed to build out my many testbeds for all the configurations of the Oracle stack I'll need. I am sure many of you out there are in the same boat!
Saturday, September 27, 2008
Oracle Open World, Titan Awards, Piocon, Events, and more...
 Well, we did it again! My company won the Titan award for the second year in a row. Actually both years was technically a Business Intelligence solution, but the project that won in 2007 was not using as many BI pieces as was possible, so we won the Health Care Industry Solution award. However, for 2008, we utilized so much BI it was crazy. Custom developed methods, out-of-the box functionality, you name it. And, as Antonio Romero (one of the OWB product managers) happens to ponder in the OWB blog below about the ROI.... let's just say it was so far beyond expectations that everyone was shocked in a good way.
Well, we did it again! My company won the Titan award for the second year in a row. Actually both years was technically a Business Intelligence solution, but the project that won in 2007 was not using as many BI pieces as was possible, so we won the Health Care Industry Solution award. However, for 2008, we utilized so much BI it was crazy. Custom developed methods, out-of-the box functionality, you name it. And, as Antonio Romero (one of the OWB product managers) happens to ponder in the OWB blog below about the ROI.... let's just say it was so far beyond expectations that everyone was shocked in a good way.
but a preview at Oracle's OWB blog: link
and a preview at our home: link
The bottom line is this. We know DW, we know BI, and we know the real business that needs to happen behind the scenes to implement a solution that is adopted and widely used to help a company. Piocon now has 2 big reasons to boast that we're the premier provider of Business Intelligence and Data Warehousing solutions for 2 years in a row.
Friday, September 5, 2008


Thursday, August 28, 2008
Techno geeks and people that love animation...
My buddy Dan Norris passed this on to me today. Simple, yet brilliant. Tech people in particular will like this, and not a bad job at all on the animation aspects. VERY cool! See it here: link
Tuesday, August 26, 2008
Laughing Squid Web Hosting » Support & Contact Information
 I love me some google blogger, because it is easier than dirt! But I've played with quite a few hosting companies and these guys (Laughing Squid) are extremely good and make life using Word Press very VERY easy. This is especially good for the non-techies or managers who just wanna blog.
I love me some google blogger, because it is easier than dirt! But I've played with quite a few hosting companies and these guys (Laughing Squid) are extremely good and make life using Word Press very VERY easy. This is especially good for the non-techies or managers who just wanna blog.
Laughing Squid Web Hosting » Support & Contact Information: "Laughing Squid Web Hosting"
OWB Interesting Warnings and Errors #1 PL/SQL: ORA-00907: missing right parenthesis
(Please remember you may click on any picture for a larger view!)
I thought while I am writing away on the new Oracle Warehouse Builder 11g Handbook for Oracle Press / McGraw-Hill that I would still put out a few simple and useful gotchas on my blog for beginner and intermediate users. The most interesting things that seem to pop up are the odd and slightly off-target errors you may receive if you do something wrong. So here is interesting warning and error #1. Relatively straight forward, but can still trick any beginner and some intermediate users.
Let us say that we have a situation that calls for using a key lookup operator. Sometimes, when the lookup results in no matching row for the input data, we have the option to tell the operator what we would like to be output (instead of plain old NULL). For example, below, I might not have a match for my incoming data for the column tgt_unit_name. If I do not, I would output a 'default value' and not simply NULL. In the case below is where my error or warning actually arises. Note that I entered 'N/A UNIT' for my default value. If I had entered N/A UNIT without the ' ' marks, this would cause OWB to complain and issue an error that might not make perfect sense to the beginner. Let us now assume that I did NOT enter the opening and closing ' ' tick marks. If I go ahead and try to validate the mapping that this key lookup operator appeared in, it would validate perfectly. Furthermore, if I decided to generate the code, and give it a once-over, it might look fine as well. However, when i go to my control center to deploy this mapping...the warnings will fire.
If I go ahead and try to validate the mapping that this key lookup operator appeared in, it would validate perfectly. Furthermore, if I decided to generate the code, and give it a once-over, it might look fine as well. However, when i go to my control center to deploy this mapping...the warnings will fire.  So the culprit is PL/SQL: ORA-00907: missing right parenthesis. If you have a nice code tool like pl/sql developer, or toad, or sql developer, you'd likely generate this code from your mapping, and throw it into your development environment and look for problems. A beginner might go right ahead and look for some missing parenthesis. Right? Wrong! This is one area in which you have to think about something. OWB creates code. Usually syntactically correct code. It will not normally and purposely create code that has missing parenthesis. The problem is somewhere else, and it deals with the fact that we did NOT put the opening and closing ' ' around N/A UNIT. See below:
So the culprit is PL/SQL: ORA-00907: missing right parenthesis. If you have a nice code tool like pl/sql developer, or toad, or sql developer, you'd likely generate this code from your mapping, and throw it into your development environment and look for problems. A beginner might go right ahead and look for some missing parenthesis. Right? Wrong! This is one area in which you have to think about something. OWB creates code. Usually syntactically correct code. It will not normally and purposely create code that has missing parenthesis. The problem is somewhere else, and it deals with the fact that we did NOT put the opening and closing ' ' around N/A UNIT. See below: We can clearly see the right number of parenthesis are there, but one is not interpreted due to N/A UNIT not being formed correctly! Let's go back to the mapping, and the key lookup operator and make sure we enter 'N/A UNIT'. (Remember, the way you interact with OWB literally is writing code.) We make the change, and deploy the mapping, and get no errors or warnings!
We can clearly see the right number of parenthesis are there, but one is not interpreted due to N/A UNIT not being formed correctly! Let's go back to the mapping, and the key lookup operator and make sure we enter 'N/A UNIT'. (Remember, the way you interact with OWB literally is writing code.) We make the change, and deploy the mapping, and get no errors or warnings!
So, what does the working code snippet look like now? Note that with a nice IDE, like SQL Developer, we can see that the moment the ticks are in place and the 'N/A UNIT' value is handled correctly in the NVL, we have success. This is to illustrate to the beginner or intermediate user that everything you do in OWB is writing code under the hood. Simply forgetting to use the tick marks to form a literal can result in an error that might make you spend many minutes hunting down a missing parenthesis! Remember that OWB generates PL/SQL, but will listen to you, the user (almost too much) and do exactly as you tell it!
Note that with a nice IDE, like SQL Developer, we can see that the moment the ticks are in place and the 'N/A UNIT' value is handled correctly in the NVL, we have success. This is to illustrate to the beginner or intermediate user that everything you do in OWB is writing code under the hood. Simply forgetting to use the tick marks to form a literal can result in an error that might make you spend many minutes hunting down a missing parenthesis! Remember that OWB generates PL/SQL, but will listen to you, the user (almost too much) and do exactly as you tell it!
Friday, August 15, 2008
ORACLE Blogs Home
Just in case you have been under a rock recently or even on vacation, here is a quality link right into the main aggregation site of ALL Oracle Corp Blogs...link
Tuesday, July 29, 2008
Thursday, July 24, 2008
Monday, July 21, 2008
Saturday, July 19, 2008
OWB patching part 2
I should have mentioned this in my first patching post a few days back. But...test test and test your patching and what it does to your system before deploying it into a secure production system.
See this OTN forums link...a few people (only 2) are having peculiar problems already with the OWB patch. This is not terribly surprising...things take a while to get perfectly right even with a patch!
Friday, July 18, 2008
Nice new Jdeveloper ( JDEV) article up on OTN
Good 'ol Shaun O'Brien has a nice new article at the top of OTN today on JDEV and some nice new add-ins and extras. Check it out! Especially nice is the discussion about Web Logic already!
Introduction
With the acquisition of BEA, Oracle has added a significant amount of technical collateral to it's already impressive listing of potential choices for project implementation. This how-to will focus on the steps necessary to make use of the same codebase under the individual flagship development environments: namely Oracle JDeveloper and Oracle Workshop for WebLogic.
The codebase to be utilized is a sample application from the Workshop side of the world, the prototypical SUN Dukes Bookstore that can be accessed at the following url: jsf-bookStore.war.
OTN
Monday, July 14, 2008
OWB patching
Just to let you all know that are still using OWB 10gR2 (quite a few I bet) it looks like there is a new patch out there that came out in July, so if you're having as issue with one of the 120 bugs it supposedly fixes, get on over to metalink to investigate the new patch!
Tuesday, July 8, 2008
What Does Oracle have in store for OWB and ODI? Here is a Roadmap!
Check out the link direct from Oracle on their plans with Oracle Warehouse Builder and Oracle Data Integrator - OWB and ODI.
check it out here.
Tuesday, July 1, 2008
BIWA Summit

All- I am going to post and link to the summit upcoming in December here, and leave a perma-link on the right side of my page if you care to visit! Go here! link
Saturday, June 28, 2008
Data Warehouse Structures: a bridge table
Bridge tables; I see this topic come up quite often. They are also known in some circles as gap tables, associative tables, helper tables, or sometimes just B tables. I have referenced a few very valuable bits about this structure below. Unfortunately, google needs a few more words than just bridge table or helper table, since the card game 'bridge' actually uses a special table, thus making the search for our info a bit harder. Sheesh! Copied here for fear they might be removed for some reason...I cannot always trust that the Internet Wayback Machine will work perfectly. So here in its original glory:
Help for Dimensional Modeling
Helper tables let you design and manage multivalued dimensions successfully.
By Ralph Kimball, DBMS online magazineThe goal of dimensional modeling is to represent a set of business measurements in a standard framework. Dimensional modeling is attractive because end users usually easily understand this framework. The schemas that result from dimensional modeling are so predictable that query tool vendors can build their tools around a set of well-known structures. The classic star join schema that results from a dimensional model usually has between six and 10 dimension tables connected directly to the fact table, as Figure 1 shows. These dimension tables have a very specific and precise relationship to the fact table.

FIG 1
Think of the fact table as a set of measurements made in the marketplace. These measurements are usually numeric and taken before the creation of a given fact table. A fact table record may represent an individual transaction, such as a customer withdrawal made at an ATM, or the fact table record may represent some kind of aggregated total, such as the sales of a given product in a store on a particular day. The dimension tables, on the other hand, usually represent textual attributes that are already known about such things as the product, the customer, or the calendar.
When you are building a fact table, the most important step in the detailed logical design is to declare the grain of the fact table. The grain declares the exact meaning of an individual fact record. In these examples, the first grain is individual customer transaction and the second grain is daily product total in the store. If the database designer is very clear about the grain of the fact table, then choosing the appropriate dimensions for the fact table is usually easy.
The secret of choosing dimensions for a given fact table is to identify any description that has a single value for an individual fact table record. In this way, you can work outward from the grain of the fact table and "decorate" the fact table with as many dimensions as you can imagine. For the ATM customer transaction example, imagine that the following dimensions all have a single value at the instant of the transaction:
- Calendar Date
- Time of Day
- Customer Account
- Physical Location
- Transaction Type (deposit, withdrawal, balance inquiry, and so on)
- Weather Summary for the Day.
These are all excellent dimensions to attach to the transaction-grained fact table record. Each of these dimensions has many descriptive attributes. The descriptive attributes are usually textual and are the basis for constraining and grouping in the user's reports. In the case of Time of Day, the textual attributes could refer to specific periods such as Morning Rush Hour, Mid Morning, Lunch Hour, Mid Afternoon, Afternoon Rush Hour, and so on. In this case, the sole numeric measured fact is the amount of the transaction. This is the basis for Figure 1.
Strict adherence to the grain definition lets you disqualify dimensions that do not have a single value for a given fact record. In the daily product totals example, you can propose the classic retail dimensions of:
- Calendar Date
- Product
- Store
- Promotion (assuming the promotion remains in effect the entire day).
But you must omit the Customer and the Check Out Clerk dimensions that you might assume would be included because these dimensions have many values at the daily grain we have chosen.
These examples give a very powerful insight. You are more likely to disqualify a dimension if you are dealing with an aggregated or summarized table. The more the fact table is summarized, the fewer the number of dimensions you can attach to the fact records. The converse of this is eye opening. The more granular the data, the more dimensions make sense. The lowest-level data in any organization is the most dimensional. This is why I argue that the "atomic data store" must be presented as a dimensional model.
Having made a pretty tidy argument for single-valued dimensions, perhaps I should consider whether there are ever legitimate exceptions. Are there situations where you might need to attach a multivalued dimension to a fact table? Is this even possible, and what problems might arise?
Consider the following example from healthcare billing. You are handed a data source for which the grain is the individual line item on a doctor bill. The data source could be patient visits to doctor offices or individual charges on a hospital bill. These individual line items have a rich set of dimensions that we can list rapidly:
- Calendar Date (of incurred charge)
- Patient
- Doctor (usually called "Provider")
- Location
- Service Performed
- Diagnosis
- Payer.
So far, this design seems to be pretty straightforward, with obvious single values for all of the dimensions. But there is a sleeper. In many healthcare situations, there may be multiple values for Diagnosis. What do you do if a given patient has three separate diagnoses at the moment the service was performed? How about really sick people in hospitals that might have up to 10 diagnoses? How do you encode the Diagnosis dimension if you wish to represent this information?
Database designers usually take one of four approaches to this kind of open-ended, multivalued situation:
- Disqualify the Diagnosis dimension because it is multivalued
- Choose one value (the "primary" diagnosis) and omit the other values
- Extend the dimension list to have a fixed number of Diagnosis dimensions
- Put a helper table in between this fact table and the Diagnosis dimension table.
Let's not take the easy way out by disqualifying the Diagnosis dimension from the design.
Frequently, designers choose a single value (the second alternative). In the healthcare field this often shows up as the primary, or admitting, diagnosis. In many cases, your hands are tied because you are given the data in this form by the production system. If you take this approach, the modeling problem goes away, but you are left doubting whether the Diagnosis data is useful.
The third approach of creating a fixed number of additional Diagnosis dimension slots in the fact table key list is a hack, and you should avoid it. Inevitably, there will be some complicated example of a very sick patient who exceeds the number of Diagnosis slots you have allocated. Also, you cannot easily query the multiple separate Diagnosis dimensions. If "headache" is a diagnosis, which Diagnosis dimension should be constrained? The resulting or logic across dimensions is notorious for running slowly on relational databases. For all these reasons, you should avoid the multiple dimensions style of design.

FIG 2
If you really insist on modeling this multivalued situation, then a "helper" table placed between the Diagnosis dimension and the fact table is the best solution. (See Figure 2.) The Diagnosis key in the fact table is changed to be a Diagnosis Group key. The helper table in the middle is the Diagnosis Group table. It has one record for each diagnosis in a group of diagnoses. If I walk into the doctor's office with three diagnoses, then I need a Diagnosis Group with three records in it. It is up to the modeler to build either these Diagnosis Groups for each individual or a library of "known" Diagnosis Groups. Perhaps my three diagnoses would be called "Kimball's Syndrome."
The Diagnosis Group table is joined to the original Diagnosis dimension on the Diagnosis key. The Diagnosis Group table in Figure 2 contains a very important numeric attribute: the weighting factor. The weighting factor allows reports to be created that don't double count the Billed Amount in the fact table. For instance, if you constrain some attribute in the Diagnosis dimension such as "Contagious Indicator" with the values Contagious and Not Contagious, then you can group by the Contagious Indicator and produce a report with the correct totals. To get the correct totals, we must multiply the Billed Amount by the associated weighting factor. This is a correctly weighted report.
You can assign the weighting factors equally within a Diagnosis Group. If there are three diagnoses, then each gets a weighting factor of 1/3. If you have some other rational basis for assigning the weighting factors differently, then you can change the factors, as long as all the factors in a Diagnosis Group always add up to one.
You can, interestingly enough, deliberately omit the weighting factor and deliberately double count the same report grouped by Contagious Indicator. In this case, you have produced an "impact report" that shows the total Billed Amount implied partially or fully by both values of Contagious Indicator. Although the correctly weighted report is the most common and makes the most sense, the impact report is interesting and is requested from time to time. Such an impact report should be labeled so that the reader is not misled by any summary totals.
Although the helper table clearly violates the classic star join design where all the dimension tables have a simple one-to-many relationship to the fact table, there is no avoiding the issue of what to do with multivalued dimensions that designers insist on attaching to a fact table. Fortunately, designers rarely insist on attaching a multivalued dimension to a set of measurements. In most cases, you have no rational basis for assigning weighting factors, or even worse, you don't have a plausible short list of candidates from the multivalued dimension. Thus you don't waste time trying to attach the retailer's Customer dimension to an aggregated daily or monthly sales fact table. It just isn't interesting or useful.
When you attach a helper table to a fact table, you can preserve the star join illusion in your end-user interfaces by creating a view that prejoins the fact table to the helper table. The resulting view then appears to have a simple Diagnosis key that joins to our Diagnosis table in the healthcare example. The view can also predefine the multiplication of the weighting factor with any additive facts in the fact table.
I have seen two other situations besides healthcare where a multivalued dimension makes sense. In addition to the Diagnosis example discussed in this column, I have built multivalued dimensions for retail banks and standard industry classifications.
Retail Banks. There are often cases where the Account Dimension is "inhabited" by one or more human customers. If the bank wants to associate individual customers with account balances, then the Account dimension must play the same role as the Diagnosis Group dimension in the healthcare example. Banks are quite interested in both correctly weighted reports and impact reports.
Standard Industry Classifications. This term defines the so-called SIC code that is assigned to a commercial enterprise to describe what industry segment they are in. The problem with SIC codes is that all big enterprises are represented by multiple SIC codes. If you encode a fact table with an SIC dimension, you have the same problem as with the multiple diagnoses. SIC codes are really quite useful, however. If you want to summarize all the business you do selling to "Manufacturers" and "Retailers" by using their SIC code, you will need an SIC Group helper table. Here's a case where with some careful thought you may assign unequal weighting factors if you believe the enterprise is mostly a manufacturer and only a little bit a retailer.
Next month I will describe a different kind of helper table for dimensions. In this case, the helper table does not describe a many-to-many relationship but rather describes a hierarchical relationship. We can use this second kind of helper table to navigate organizational hierarchies and manufacturing parts explosions.
Friday, June 20, 2008
On the OTN forums lately...
I have taken a brief reprieve from my blogging for a bit so that I can contribute more to the OTN forums. I have been posting anything from 1-5 replies daily if I think I might be able to help anyone with what I know. I think a lot of my postings have been in the OWB area for now.
I'm likely going to Oracle Open World this year, as I got an invite with the nice free full conference pass. I am not sure I'd go without that thing being somehow covered! :) Hopefully I'll see my Oracle friends out there, and my family who (some of them) live in the bay area, as well as old school friends in SF and Oakland that went to Berkeley and my old U of I buddies that live in the Silicon Valley now.
Woohoo!
Wednesday, June 11, 2008
OWB can be a bit 'blind' when Oracle RAC is involved!
I will update this bit soon I hope. I'll post a little nasty bit that tricked us and cause our mappings to run horribly slow on a RAC environment. Hopefully when I get a little more information on RAC from Dan Norris, I'll update this with a clear explanation!
Saturday, May 31, 2008
OWB 11g R2 beta and book
Good news! I have been accepted into the OWB11gR2 beta, and I am putting the new features though the testing ringer to see just how well everything will turn out. I will likely not be able to mention or discuss much of it, so please don't ask. If I have been given consent, I will share at the approved time.
I am also in the early stages of bringing a massive amount of experience, projects, data, and writing manuscripts together for an even bigger project. I'll be starting very soon to write the first Oracle Warehouse Builder book ever published. It will be with Oracle Press (McGraw Hill) and will be taking advantage of all the beta experience that will be gained from the OWB11gR2 beta.
In the coming months I will update here on anything that is allowed and not confidential.
Saturday, May 10, 2008
Chicago Oracle User's Group this Monday!
Anyone in the the Chicago area should not forget the Chicago Oracle user's Group! My colleague Dan Norris will be speaking on Oracle Adaptive Access Manager and security in general. This will take place this coming Monday in Chicago (where else??) Check it out here! link
Data integration is not necessarily creating you a Data Warehouse
Nice quick read, but older article! link
Wednesday, April 2, 2008
Oracle Warehouse Builder OWB vs. Oracle Data Integrator ODI
Here's a snippet from a bigger article written by Mark Rittman over on OTN.
Oracle Data Integrator in Relation to Oracle Warehouse Builder
At this point, regular users of Oracle Warehouse Builder are probably wondering how Oracle Data Integrator relates to it and how it fits into the rest of the Oracle data warehousing technology stack. The answer is that Oracle Data Integrator is a tool that’s complementary to Oracle Warehouse Builder and can be particularly useful when the work involved in creating the staging and integration layers in your Oracle data warehouse is nontrivial or involves SOA or non-Oracle database sources.
For those who are building an Oracle data warehouse, Oracle Warehouse Builder has a strong set of Oracle-specific data warehousing features such as support for modeling of relational and multidimensional data structures, integration with Oracle Business Intelligence Discoverer, support for loading slowly changing dimensions, and a data profiler for understanding the structure and semantics of your data.
Where Oracle Data Integrator provides value is in the initial preparation and integration of your source data, up until the staging area of the data warehouse.

Oracle Data Integrator can integrate and synthesize data from numerous disparate datasources, including Web services and event-based architectures, and, as shown in the figure above, provides a handy graphical interface on top of Oracle Database-specific features such as Oracle Change Data Capture. Once data has been integrated and copied into your data warehouse staging area, Oracle Warehouse Builder can take over and create and populate your operational data store and dimensional warehouse layers.
Saturday, March 29, 2008
Do certifications always prove you're qualified to do the job?
Recently, I have come to the understanding that many certs fail to really certify whether or not someone can truly master material and do an effective job. There are quite a few individuals who are just very good test takers or students, if you will, and they study very hard or take expensive 'crash-courses' to help them pass with a high score.
There are a very few amount of certifications that I believe don't fail however. I can honestly say I have NEVER met someone that became an 'Oracle Master' that really wasn't at least a 7/10 on a 10-point scale. (Most DBAs being 3, 4 or 5.) Someone like Tom Kite or Kevin Loney being around the 10 range. This certification, of course, requires you to take hands on labs that are very difficult and stressful, along with prerequisite certifications and courses.
On the other hand, a very popular certification that seems to garner a lot of attention is PMI's PMP cert. This is for project management. Unfortunately, employers drool over this certification. PMI tried to do an extensive job of screening out people that are even allowed to TAKE the exams by having you fill out how much management work you've done, references, companies, and the whole 10 yards. Unfortunately, employers seem to feel that this means PMI has cleared this person as a top proj manager, and they don't have to have their own proven, top level project managers interview them on their PM skills and abilities.
Because of this, you have people that have 'hacked' their way through the PMI process unfairly by barely qualifying or by manipulating the system, then they take expensive crash courses, and they pass with a high score- BUT they have never truly managed a highly stressful and big-money project! They sometimes even ignore the holy trinity of constraints- resources, time, and project scope!
Does this mean a cert like the PMP is junk? Absolutely not. But it needs to be taken cautiously, and not frivolously. Interview these PMP's with your own proven top-level PMPs and see if they really can pull their weight. If you have a PMP with 20 years experience, vs one with 8-10...well, you can do the math.
Do your homework ahead of time, and make sure the PMP you're hiring is proven- and not just from the references THEY give you! Putting an PMP in charge of a project that could jeapordize the project is very dangerous, and you sadly don't realize this until the project is hitting it's critical points!
Friday, March 28, 2008
SQL Developer and the TNS Connection Type Selection
I will be exploring this much further soon, but suffice it to say, sometimes when you install SQL Developer or other Oracle tools, they look at the most recent Oracle home from a new Product install. For example, I installed OWB, and it had a new home. This actually overwrote some of the paths in the Operating System, and defaulted that home as the 'main' home.
Well a tool like SQL Developer loads a nice TNSNAMES.ora listing of all your database connections and it searches through that default home. If it looks at a new home that doesn't have those listings, you drop down will have no available connections!
A VERY easy way to fix this is to launch the universal installer, look at all installed products, and while looking at the oracle homes on your box, you can use the up and down arrows on the right panel to 'rank' or put a certain oracle home as the 'main' or default home. Doing this, I then put my original database home as the default. I restarted SQL Developer, and bingo! It then read the right oracle home and the right TNSNAMES.ora entry and populated the drop down.
Not bad!
Wednesday, March 26, 2008
Oracle Warehouse Builder OWB 10gR2 Tutorial for you!
Here's a set of slides with some basics of OWB for beginners to look over. I know Oracle has some Oracle By Example tutorials that are 'OK' at best. This is another look at the tool for you to learn from. Hopefully these will fill in some gaps as the documentation is not so great, there are no OWB books, and there is not as much useful information about this product compared to other Oracle products.
Tuesday, March 25, 2008
What the Oracle Database can do for your Data Warehouse
There are many MANY times I write a particularly difficult query or PL/SQL package and I realize that I am re-inventing the wheel. Reinventing the wheel = BAD. (unless there is something nifty in there that hasn't been done before).
I wanted to make a quick list of links to various tutorials, articles, and direct bits of Oracle docs that will get you to understand and learn some of the database provided tools that can make your SQL writing and Data Warehouse tuning and building much easier. Some of these tools are not always easy to use the first time, but they will be easier to learn than forcing yourself to build them (or rebuild the wheel).
I'll post the 10g features for now. I'll try to get back and post the 11g features and how they work as well. Suffice to say, the 10g features are in 11g and some are enhanced. These can really save you some time. Usually the hard concepts and difficult things you seek to do are already here.
For example, how many times have you had to do some pretty tough hierarchical processing (parent-child relationships) but never used the SQL connect-by query clauses?? These parent child relationships are extremely common in a Data Warehouse.
SQL Model Calculations
The MODEL clause enables you to specify complex formulas while avoiding multiple joins and UNION clauses. This clause supports OLAP queries such as share of ancestor and prior period comparisons, as well as calculations typically done in large spreadsheets. The MODEL clause provides building blocks for budgeting, forecasting, and statistical applications.
link
Materialized View Refresh Enhancements
Materialized view fast refresh involving multiple tables, whether partitioned or non-partitioned, no longer requires that a materialized view log be present. The second link I provide here is particularly useful because it has screen shots and walk throughs to help you with MVs. Getting MVs to work well with fast refresh can take a little patience with all of their prerequisites!
link
link2
Query Rewrite Enhancements
Query rewrite performance has been improved because query rewrite is now able to use multiple materialized views to rewrite a query.
link
Partitioning Enhancements
You can now use partitioning with index-organized tables. Also, materialized views in OLAP are able to use partitioning. You can now use hash-partitioned global indexes. I also wrote a nice article in the IOUG BIWA (business intelligence, warehousing, and analytics) SIG's newsletter on the 11g database enhancements to partitioning, if you want to dig up their publications!
link
Change Data Capture
Oracle now supports asynchronous change data capture as well as synchronous change data capture.
link
ETL Enhancements
Oracle's extraction, transformation, and loading capabilities have been improved with several MERGE improvements and better external table capabilities.
link
Thursday, March 6, 2008
Should I buy an iPhone...once again-
I merely wanted to add this link. I have thought for a long time that this device lacked some enterprise level authority, and it looks like they will address that with the next release.
Check it out at this link to read the summit and SDK dicsussions...link
Peronally, this goes a long way for me...using VPN, exchange sync'ing, that is some decent thought there!
I might get one (when the price is under $500!)
Friday, February 22, 2008
Should I buy an iPhone?!
I have seen more and more iPhones make their way into offices at my clients. I don't trust online surveys and online critiques as much as I trust live people using one. So, I decided to start asking every person I know and that I meet, "How do you like it?"
I asked them, " If you chould change anything about it, what would it be?"
"Any problems?"
"Have you had a better phone?"
"Reception quality?"
I ran the full gauntlet of questions and even got to play with their phones.
Surprisingly, the amount of complaints was VERY minimal. Price being the only downer thus far, and a few people complaining about the EDGE network and how it goes down, and how once in a while a call is dropped when travelling between 2 connection points. That was about it.
All in all, very few negatives and the positives they mentioned FAR surpassed the bad.
Now I have to take the question more seriously, "Will I get one?!"
Wednesday, February 20, 2008
Oracle Warehouse Builder OWB 11g New Features Part 6!
This is a continuation from part 5. In part 6, we will discuss a bit more about the installation of OWB 11g, and the install options. Again, thanks to Oracle for providing some of this information to make my posting easier!
Server Install Provides Full Control Center Functionality

The Oracle home of the Oracle Database 11g installation includes the components needed to perform the following tasks for OWB:
- Deployment and execution of all standard objects
(tables, dimensions, cubes, maps, and so on) - Deployment of process flows
- Warehouse upgrade
- Run-time scripting
- Installation of Oracle Workflow
The OWB server installation includes a small set of files needed to get the Control Center running in the database Oracle home. This allows a “fully functioning” OWB install directly with the database install.
The directory structure looks like this:
- Oracle Home
/owb - Oracle Home
/owb/wf
Discoverer deployment is the only task not supported by the OWB server install. For Discoverer deployment, you must perform the stand-alone installation described later.
Stand-Alone..When Do You Need Stand-alone Installation?

The OWB 11g stand-alone installation is required only if you must:
- Deploy to an Oracle Database 10g, release 2 target
- Perform Discoverer deployment
The stand-alone DVD is actually bundled with the 11g database pack.
For full functionality, OWB 11g stand-alone must be installed on the database server machine (10g R2 or 11g) into a new Oracle home (separate from the database home).
Using OWB 11g with DB 10g R2

OWB 11g is architected on the assumption that it will be used with Oracle Database 11g. This tight integration includes pre-seeding of the OWBSYS schema in the default database and placing OWB in the same Oracle home as the database.
To use OWB 11g with Oracle Database 10g R2, you must perform a few simple steps:
1. Run SQL script to create OWBSYS.
2. Run SQL script to identify OWB home to Oracle Database 10g R2.
3. Unlock OWBSYS.
4. Enable access to workspaces.
1. Run SQL script to create OWBSYS.

When using Oracle Database 10g R2, you must run a SQL script to create the OWBSYS repository schema that is needed by OWB 11g. (OWBSYS is automatically created during Oracle Database 11g installation, so this step is not needed when using OWB 11g with Database 11g.)
The script
Note: The method by which you invoke SQL*Plus is important. Do not invoke SQL*Plus from the Start > Programs > Oracle database home folder or the Warehouse Builder folder. Instead, invoke SQL*Plus from Start > Run > cmd.exe. Type the Path command and press Enter.
Verify that Warehouse Builder is near the front of the path statement so that the SQL*Plus session invokes from the Warehouse Builder installation. If not, you may need to temporarily set the path (such as Path=
sqlplus sys/
Connect to SQL*Plus as SYSDBA and issue the following command to create OWBSYS:
@
Press Enter. You are prompted for a tablespace for the OWBSYS user. Type a table such as users and press Enter.
When this command finishes successfully, you are prompted: “If you are NOT using an OWB installed in the Oracle database home, please now run reset_owbcc_home”.
2. Run SQL script to identify OWB home to Oracle Database 10g R2.
Earlier, you were instructed to install Warehouse Builder in an Oracle home other than the database Oracle home if you are using OWB 11g with Oracle Database 10g R2. To ensure access to the Control Center on the Oracle Database 10g R2 database, run the reset_owbcc_home.sql script and pass in your Oracle home for Warehouse Builder.
Run the script as a system privileged user such as SYS or SYSTEM. For example, type the following command at the command prompt:
SQL> @c:\oracle\OWB_home_11g\owb\UnifiedRepos\reset_owbcc_home;
Press Enter. You are prompted for the full path of the Oracle home for the OWB Control Center install. First read the following note.
Note: In the following example, observe the required use of the forward slashes (/) even when using a Windows machine. Note also that your response with the full path must be case sensitive. Be sure to enter the drive letter in uppercase (such as C:) and follow the case sensitivity of the folder names in the path of the Oracle home for OWB. Your response should be similar to the following example:
C:/oracle/OWB_home_11g
Press Enter.
Important note: If you specify the path to the OWB Oracle home incorrectly (using backward slashes or incorrect case sensitivity), the reset_owbcc_home.sql script finishes without apparent errors. However, when you later use the Repository Assistant to create a workspace and users, the process fails.
3. Unlock OWBSYS.

After creating OWBSYS, you must unlock the OWBSYS account and reinstate its password if the strong password option is enabled on the database. Proceed with the SQL*Plus commands to unlock the OWBSYS account and assign a password (also named OWBSYS):
alter user OWBSYS account unlock;
alter user OWBSYS identified by OWBSYS;
The requirements explained above are also mentioned in the OWB 11g Installation Guide documentation, in the section titled “Hosting the Repository on Oracle Database 10g Release 2.”
For each Warehouse Builder client installation, enable access to the workspaces hosted on your Oracle Database 10g R2 database.
4. Enable Access to Workspaces
By default, Warehouse Builder 11g, release 1 clients are set to connect to workspaces hosted on an Oracle 11g database. That is, the Warehouse Builder repository is assumed to be hosted on an Oracle 11g database.
To enable access to an Oracle Database 10g R2 repository and its workspaces, alter the file
In the preference properties file, add the REPOS_DB_VERSION_ALLOWED property and set its value to Oracle 10g, Oracle 11g. (This property may already be present.)
And that's all for part 6. Hopefully, this allows users to get OWB 11g installed in their preferred format! Thanks again to Oracle for providing some of the info contained above. If you have any questions, feel free to drop me a line. Part 7 will cover Repository Assistant Workspace Changes, and how logging in, managing users and targets, and other features have changed!
Monday, February 18, 2008

Wednesday, February 6, 2008
What is BAM and what does it have to do with Oracle?
I've heard the term tossed around quite a bit. BAM. I've heard it used in many different ways, some wrong, some VERY wrong, and a few right. So, with an audience reading, here is what I have gathered, read, researched, and know about BAM and what Oracle is doing with it:
“BAM defines the concept of providing real-time access to critical business performance indicators to improve the speed and effectiveness of business operations.”
-The Gartner Group
-The Gartner Group
OK, so going off of that 'authoritative' quote, let us break this down. 

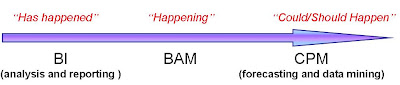
- •BAM is largely born-of, and is reshaping, two previously distinct technology markets:
- –Analytics and decision making of Business intelligence market
- –Real-time and business process linkage of Enterprise Application Integration (EAI)
- •BAM focuses on what is happening, not what has, or might happen
- •BAM sits in-between the historical and analytical focus of BI and the forward business planning of Corporate Performance Management

BAM applications monitor day-to-day business processes such as customer orders, insurance claims and supply chain operations. BAM products are typically driven by process models. This is very different from data-driven ETL applications, which have little or no knowledge of business processes. (Aside: it is worth mentioning that strategic and tactical performance management is also likely to become business process driven in the future.)
As a BAM server tracks operational events, it maintains these events in a cache that is used by a reporting and analysis engine running under the control of the BAM server. The analysis engine can access existing business intelligence and data warehouse information to put the operational events being tracked into a business context and produces scorecards of operational business performance. The BAM environment, however, also provide the ability to do more detailed analysis and mining of information in the analytics engine.
The key benefit of a BAM environment is that operational processes can be monitored and exceptions acted on in close to real time.
Another recent trend in BI analysis tools has been to add a performance management capability that enables business users to compare the analytics produced during BI processing to actual business goals and forecasts (i.e., it puts BI into a business context). Performance management products extend the use of BI from measuring business performance to managing it. This is termed as Business Analytics. The actionable intelligence produced by these products is presented in the form of drillable scorecards that employ formal or informal methodologies to document business goals and initiatives. Some performance management products also provide rules-driven facilities to send alerts to business users when thresholds defined by the user are, for example, not achieved. Alerts reduce the amount of time business users spend in accessing and analyzing data, and reduce the reaction time required to identify and fix business problems.
BI and Business Analytics tools enable business users to react to business situations after they occur. Their predictive analytics tools component adds techniques such as data mining and forecasting to a business intelligence framework. These techniques help users to become more proactive in managing the business. In some cases, predictive tools are used to provide the business context (e.g., rules, forecasts) for the scorecards and alerts used by performance management tools.
- üBAM adds real-time information to Business Intelligence
- üBusiness Intelligence adds information context to BAM
Both BI and BAM address the needs of monitoring business processes to enhance operations efficiency. The key differentiator relates to the how quickly the business needs to react to an event or process exception. Business problems that require near real-time information access and analytics can be best solved using BAM.
BAM furthers the BI cause by:
1. Embedding key analytics (computed in real-time) in day-to-day business processes
2. Correlating heterogeneous events and patterns to compute causalities, aggregates and thresholds, based on end-user preferences
3. Delivers the analyzed information and alerts in real-time to the users when and where the information matters
4. Providing a platform for structured and collaborative problem resolution
Using a loan as an example, BAM can send an alert to indicate a number of loans have been made in a specific area. This is very useful information, but becomes more useful when used with BI to see what the impact of these loans have on an organization's exposure in different markets. BI can put the results of BAM into a broader context and make the decision process a more informed one.
It may be that as an organization, analysis results show exposure is becoming too skewed toward a specific market. As a result of this analysis, the BAM thresholds for sending alerts can be adjusted. You make the rules, you set the thresholds, you learn real-time when these thresholds are at or near being hit.


There will be a part 2 of this article shortly which will explore the technical and business challenges of implementing BAM. Stay tuned...
Who uses BAM?? (click any picture to enlarge)

There will be a part 2 of this article shortly which will explore the technical and business challenges of implementing BAM. Stay tuned...
Tuesday, February 5, 2008
Oracle Warehouse Builder OWB 11g New Features Part 5!
This is a continuation from part 4. In part 5, we will discuss a bit about the installation of OWB 11g, and how it is easier and differs from the previous counterparts. Again, thanks to Oracle for providing some of this information to make my posting easier!
Overall, the installation of OWB 11g is greatly simplified in an Oracle Database 11g environment. When you install the core Oracle Database 11g, you get the OWB back end: a pre-seeded repository schema and workflow.
Without the requirement of SYSDBA privileges (as we previously mentioned in other postings), you can make a sandbox repository and start exploring the OWB tool immediately! This was not necessarily so in the 10g versions!
Three types of OWB 11g installation possibilities can be:
- Server installation as part of the Oracle Database 11g installation
- Stand-alone installation using the stand-alone DVD bundled with the 11g database pack
- Stand-alone installation for Oracle Database 10g R2 using special scripts
- Note: Installing to Oracle Database 10g R2 requires running two special SQL scripts and a few extra steps

OWBSYS Is Part of Database 11g Installation
As part of the database installation scripting, the OWBSYS schema is seeded as part of these starter databases:
- General Purpose
- Transaction Processing
- Data Warehouse
During installation, all of the necessary system privileges, object privileges, and roles are granted to the OWBSYS schema. The script that creates OWBSYS is located at: ../owb/UnifiedRepos/cat_owb.sql
 Why?
Why?
So after database installation, OWB is ready to use. Because the necessary privileges and roles are granted, no DBA or SYSDBA credentials are required when creating workspaces.
Note: The schema does not hold a complete repository/workspace in its pre-seeded form. You must still define your workspaces, workspace owners, and users. Also, OWBSYS is locked by default. As will be explained later, you must unlock it if you are using OWB 11g with Oracle Database 10g R2.
OWB as a Custom Database Option
For custom databases, OWB is an option in the Database Configuration Assistant user interface. With the OWB option selected, these database options are enabled:
- Oracle OLAP
- Oracle JVM
- Oracle XML DB
- Oracle Intermedia
- Oracle Enterprise Manager Repository

Now that we have a brief overview of the install options, next time we will look more in depth at the OWB 11g server install, the OWB 11g standalone install, and if the post doesn't get TOO long, we'll also discuss using OWB 11g on a 10gR2 Oracle Database and all the gotchas that come with that! I know that will be heavily requested just simply because some people want to use OWB 11g but don't want to upgrade their database just yet from 10gR2 to 11g! Until next time....
Monday, February 4, 2008
Lesson learned: New England Patriots and your fans...
cheaters, you got what you deserved. :)
18-0 with 1 GIANT mistake. :)
Monday, January 14, 2008
Bi Publisher and nested tables and loops
One thing I have noticed while developing RTF templates is that it always seems to be in your favor to try to use tables to structure your data. Not only this, but using or not using tables, depending on your XSL logic, can actually greatly change the output of your BI publisher report.
The following post will illustrate a few things I went through while developing a report that had a strict heirarchy. Now, this report is based off of an Oracle Apps Bill of Lading, and combined a bit with a Sales Order Acknowledgement document, so it might not look familiar. The point is, there are a few steps in understanding how to get your report looking right.
1. Understand what data needs to be on the report and HOW it needs to look and be structured.
2. Become familiar with the data and how it is structured hierarchically or if at all.
3. Become intimately familiar with your query or tool (like Oracle Reports) that needs to generate
the XML that your BI Publisher template will merge with.
4. Review your XML that is merging with the template so you truly understand what data is at what
level in the hierarchy, and where it might repeat as a group.
5. Learn to re-structure your report or application that serves the XML so it fits your needs.
6. Finally, learn to use BI Publisher's templating ability (and tables) to produce the output in the right
format.
That being said, for our example we will look at a heirarchy as follows:
LPN (license plate number) is the master node or top-most level.
- Item Number and Item Description are just underneath LPN, and there might be multiple
entries PER LPN.
- Quantity, Lot Number, Heat Number, and Mechanical Number are all attributes of an item
number, and thus they can all appear multiple times PER item number.
The XML data might look like:
Mechanical Number- 339394
Note that this is the easiest situation, 1 LPN, 1 'set' of item description and item number, and 1 'set' of the item's attributes underneath. We need to design the BI Publisher template for a repeating possibility though, like:
LPN 1
ITEM 1
.
.
ITEM Attributes N
.
ITEM N
.
.
.
LPN N
So multiple possible LPNs each with multiple possible items, each with multiple possible attributes. And yes, the people that read this report want it grouped nicely so that each attribute belonging to each item belonging to each LPN is 'grouped' and structured hierarchically. For any experienced reporting developer or any data analysis professional, this isn't too bad. However mastering this in BI Publisher with MS Word as your RTF Template tool, you really should master nested tables. The following is a screenshot of how we can get this to work in a report. It is a simple shot of the most basic situation with only 1 LPN, 1 item and 1 description. note the nested tables in this output:
The next shot is a more complicated output using the SAME template, this one having multiple items and descriptions for 1 LPN:
Again, notice the structuring of the tables I purposely left so you can see how this is built from top to bottom. You need to nest your tables hierarchically to get this structure to work.
Finally, the template and the XSL and code:
A few things to note in this quick template, we are indeed using barcodes as you might have noticed. Our initial for-each tag (in aqua) is outside the main table and will repeat basically for every single occurence of an LPN. Then we have a table nested inside the LPN table. This next FE (for-each) is shown in the 2nd nested table and it will repeat for each occurrence of an item number and item description pair. Finally, we nested a 3rd table inside the item's table, and it holds the item's attributes. The 3rd and final FE (for-each) will repeat for each Quantity, Lot, Heat, and Mechanical ID attributes it finds for the current item. You'll then see the EFE (end for-each) that stops the repeating for each of the 'FE' sections.
We also have a XSL tag that says split-by-page-break:
This is a tag that needs to be experimented with and placed JUST BEFORE the right EFE tag to see what it does. If done right, it will page break at the end of each of the elements for the EFE it proceeds. In this case, the tag is just before the last EFE which is related to the initial FE which if for the repeating LPN. So it will page break for each LPN we encounter...and it does. It keeps all items and attributes together but only makes a new page when the LPN changes.
Hope this helps!
Subscribe to:
Comments (Atom)

